
Example Output from LLaVa-13B
Below is one of the examples output from LLava-13B
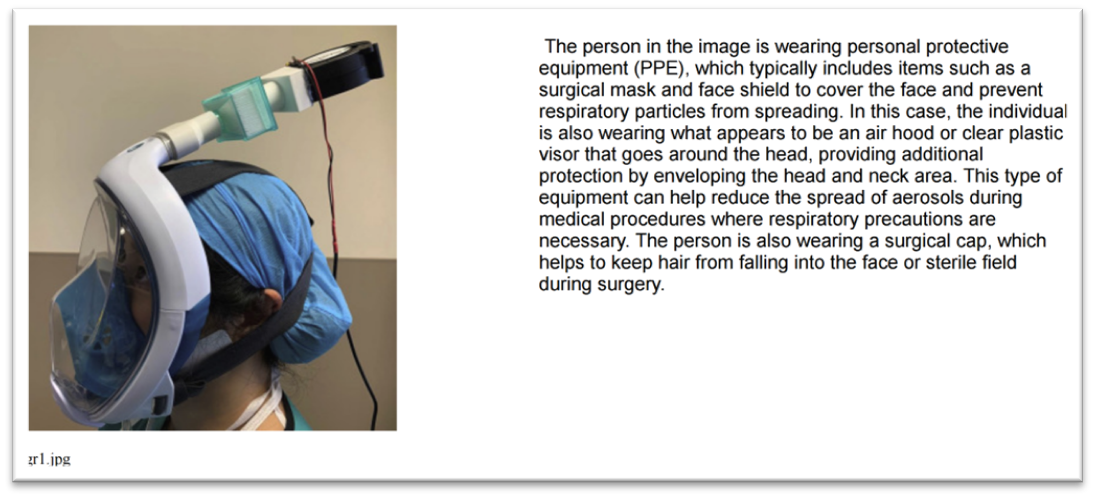
1 Example from LLaVa-13B for one image
Same example from LLaVa 7B
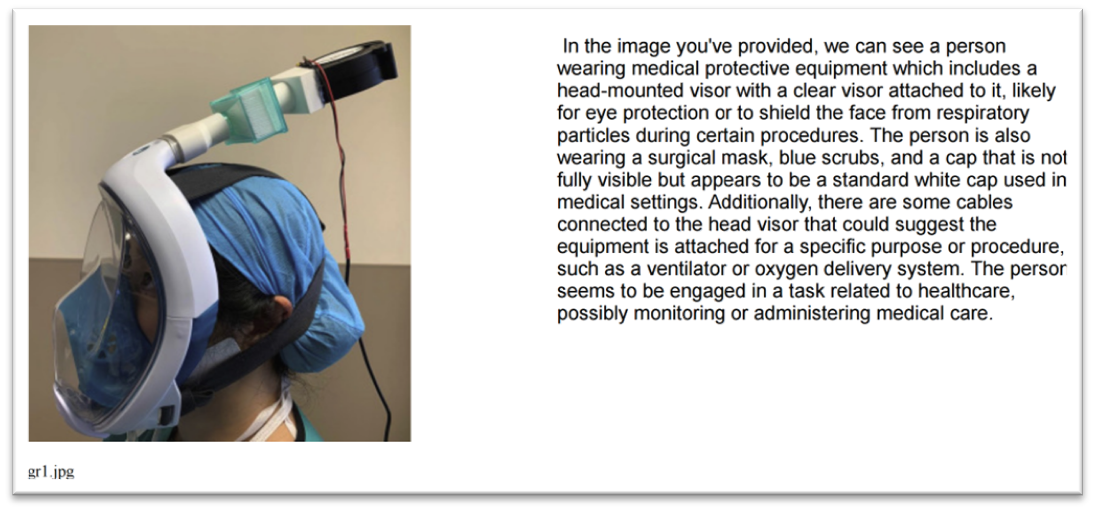
2 Example from LLaVa-7B for same Image
Key Takeaways from the OllaMa-based Phase
Beyond the specific PPE detection capabilities, this phase revealed important insights about using VLMs for custom annotation tasks:
- Rapid Prototyping: The OllaMa library enables quick experimentation with VLMs for different annotation scenarios, allowing teams to quickly assess whether VLMs are suitable for their specific use case.
- Natural Language Interface: The ability to use simple prompts makes VLMs accessible to domain experts who may not have extensive computer vision expertise.
- Annotation Consistency: While not perfect, VLMs showed promising consistency in identifying subtle variations in PPE types, suggesting potential for reducing annotation variability.
- Limitations in Specialized Contexts: The quantized nature of these models highlighted the importance of carefully evaluating VLM performance on domain-specific elements.
Below example is the output of Ovis1.6-Gemma2-9B model.
 3 Example from Ovis1.6-Gemma2-9B Model
3 Example from Ovis1.6-Gemma2-9B ModelKey Takeaways from the Transformers-based Phase
The Transformers-based approach revealed additional insights about VLMs as annotation tools:
- Annotation Flexibility: The ability to experiment with different VLM models allows teams to find the best fit for their specific annotation requirements and domain constraints.
- Integration Potential: The robust Transformers ecosystem makes it easier to integrate VLM-based annotation into existing data processing pipelines.
- Performance Trade-offs: While potentially slower, these models demonstrated higher accuracy in detecting subtle variations, which is crucial for specialized annotation tasks.
- Customization Options: The framework’s flexibility enables teams to fine-tune the annotation process for their specific industrial context.
Experimental Evaluation and Results Analysis
To rigorously assess the VLMs’ capabilities for industrial annotation tasks, we conducted a comprehensive manual evaluation of their performance on our custom PPE dataset. This evaluation was particularly important given the lack of traditional ground truth annotations, reflecting real-world scenarios where existing annotations may not be available.
Dataset Categorization and Evaluation Metrics
We categorized the test images into three complexity levels to better understand the models’ performance across different scenarios. We have 3 image complexity levels “Complex”, “Moderate” and “Simple”.
Given the qualitative nature of VLM outputs and the absence of confidence scores, we developed a three-tier accuracy assessment framework, where we are categorizing them into “High Accuracy”, “Moderate Accuracy” and “Low Accuracy”.
Further details on Dataset and Evaluation matrix can be found on our GitHub Evaluation
Performance Visualization
We have consolidated the results from different models and we created Stacked Bar Chart which shows the accurate comparison between the models.
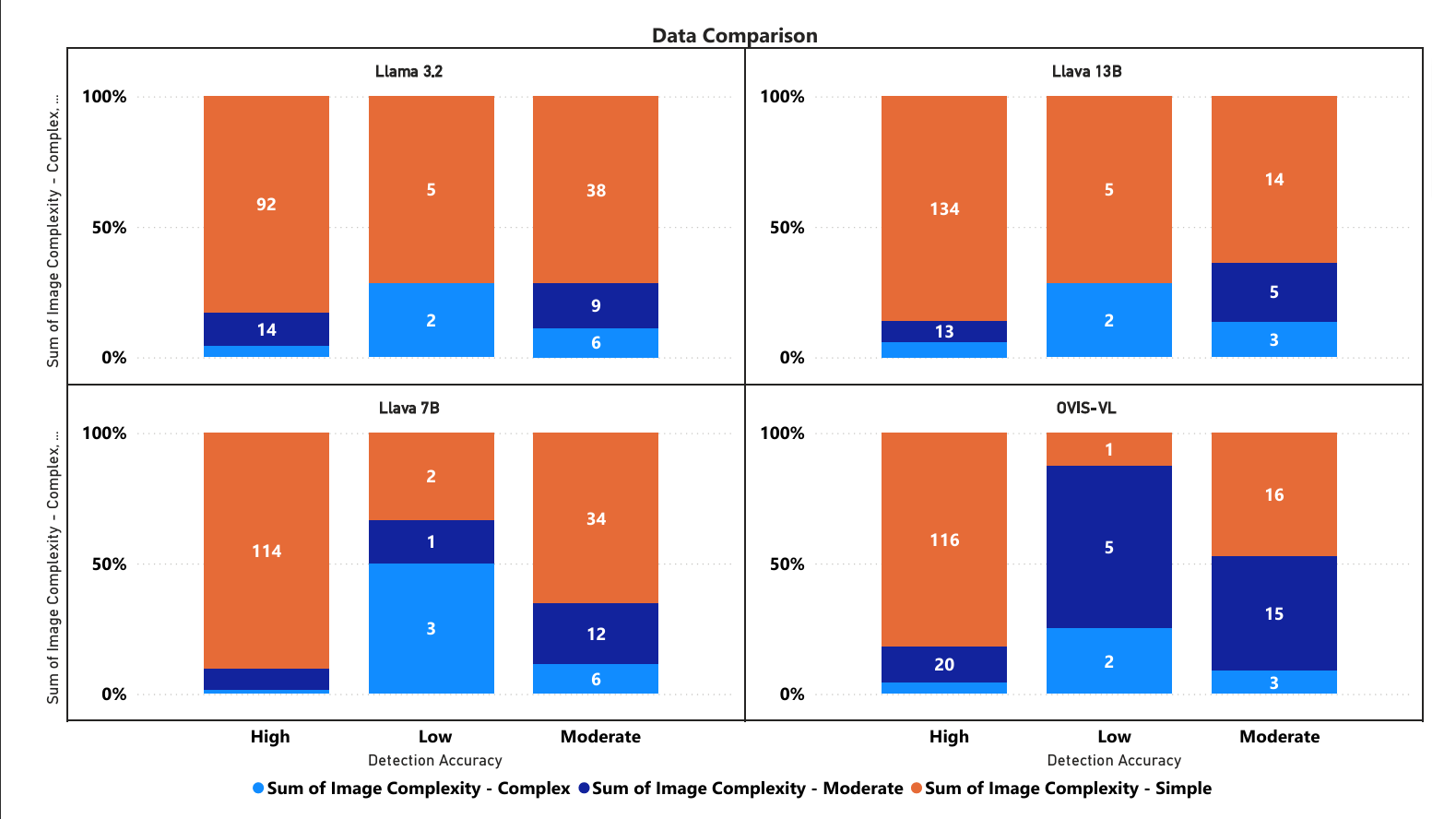
4 Consolidated Graph for LLaMa3.2-Vision, LLaVa-131B, LLaVa-7B, Ovis1.6-Gemma2-9B
Observations:
- All models handle simple images (orange) well at high detection accuracy
- Llava 13B shows strongest performance with 134 simple image detections at high accuracy
- Complex images (blue) generally have lower detection counts across all models
- Low detection accuracy category shows smallest total numbers across models
- OVIS-VL appears to handle moderate complexity (dark blue) images better than others
The y-axis shows percentages stacked to 100%, while numbers inside bars represent actual counts. Each model’s performance is evaluated based on how well it handles different image complexities at varying detection accuracy levels.
